Tras el resumen del primer día, vuelvo con las charlas en mi segundo día en la CAS 2014, contadas desde mi punto de vista como informático y programador.
Keynote Beyond Budgeting – Bjarte Bogsnes
Bjarte abrió el segundo día explicándonos los conceptos de gestión que expone Beyond Budgeting.
Nos hizo reflexionar sobre las situaciones absurdas que se producen al manejar la empresa con presupuestos monetarios, como no poder presentar un nuevo proyecto en diciembre por el hecho de ser diciembre, o tener que gastar todo el presupuesto para que no nos asignen menos la próxima vez.

Una de las metáforas de gestión que utiliza es la gestión del tráfico mediante semáforos o mediante rotondas, haciendo ver que el tráfico es mucho más fluido con rotondas. De hecho en ellas se producen menos accidentes.
Como pega a la comparación, creo que a Bjarte le faltaba conocer cómo se toman las rotondas en España…
Por último nos contó su experiencia en Statoil (Compañía energética noruega), y lo que supuso el cambio a un modelo más ágil.
La compañía expone de manera gratuita un libro sobre cómo realizan ellos la gestión: The Statoil Book.
Si queréis más información sobre la charla os recomiendo este artículo y por supuesto su libro.
Generando tests – Rafael de Castro
En esta charla aprendí algo que me era completamente desconocido, además el título no me decía mucho, así que me llevé una gran sorpresa con todo el provecho que saqué.
Descubrí la existencia y uso de tests basados en propiedades o post-condiciones, en este caso con Scala.
Rafa nos ilustró con un ejemplo sencillo cómo se nos pueden colar cosas no probadas al hacer los test unitarios.
Abundó en la idea lanzada por José Armesto el día anterior de la seguridad que deben aportarnos los tests de los que disponemos.

Si nos encontramos con el caso, disponemos de esta técnica, un poco a modo de “Piñata bug hunting”, donde probaremos propiedades o postcondiciones que deben ser cumplidas, como por ejemplo que aplicar una operación y después la operación contraria debe dejar el sistema en el estado inicial.
Se nos presentó para ello ScalaCheck con Scala, y otras alternativas como test.check para clojure, o Rantly para ruby.
Mediante el uso de Generadores crean entradas aleatorias para probar las propiedades. Los generadores pueden ser de tipos simples o clases propias.
Esto hace que no sean test unitarios, ya que no son repetibles, y dependiendo de la prueba pueden ser lentos.
Vimos un ejemplo de postcondición en una aplicación de una tienda donde los productos y el total nunca deben tener valor negativo, y vislumbramos el potencial de estos test al generar comandos aleatoriamente.
Todo esto hace que sean test que van muy bien para ejecutar en la integración continua, o en builds nocturnas.
Por supuesto no sustituye a TDD, Rafa dejó ahí su sutil crítica a DHH.
Por último la recomendación del libro ScalaCheck, the definitive guide.
CQRS y los beneficios surgidos de la necesidad – Ricardo Borillo
Ya está disponible su presentación aquí.
Fue una exposición muy interesante sobre el patrón Command Query Responsibility Segregation, sus usos, su combinación con Event Sourcing, lo que aporta a la resolución de qué problemas, y sus desventajas.
No es una ‘bala de plata’, pero viene muy bien en ejemplos como el mostrado, consistente en una web con una tienda típica donde sucede la siguiente situación:
La gente agrega cosas al carrito, en algún momento borra cosas del mismo, y efectúa la compra.
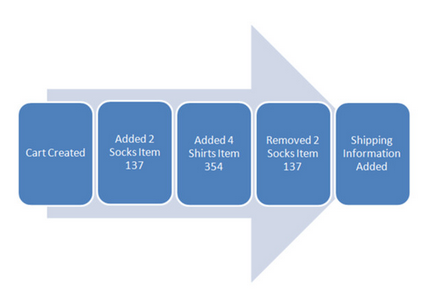
CQRS viene al rescate cuando queremos además aprovechar la información de los productos que se borraron de la lista, y explotarla por ejemplo con un sistema de Business Intelligence.
Se puede empezar a usar el patrón simplemente como buena práctica de separación de responsabilidades, separando por un lado los Commands de las Querys, es decir, las peticiones de escritura de las de lectura.
Los commands serán por tanto peticiones que modifican el estado del sistema y que normalmente serán solicitadas por el usuario desde la interfaz.
Las querys no modificarán el sistema, pero servirán por ejemplo para alimentar cuadros de mando que nos den información de lo que pasa.
La combinación con Event Sourcing surge al guardar en nuestro almacen de datos los commands en forma de eventos (o peticiones de modificación), en lugar de almacenar directamente los datos.
Como ventaja añadida, al almacenar las acciones, podremos reconstruir el estado del sistema en cualquier momento del pasado, lo que puede venir muy bien incluso a la hora de reproducir bugs.
La gran ‘desventaja’, o más bien algo que debemos asumir desde el principio, es la consistencia eventual entre el almacén de eventor y el almacén de datos que por ejemplo alimente a nuestro sistema de BI.
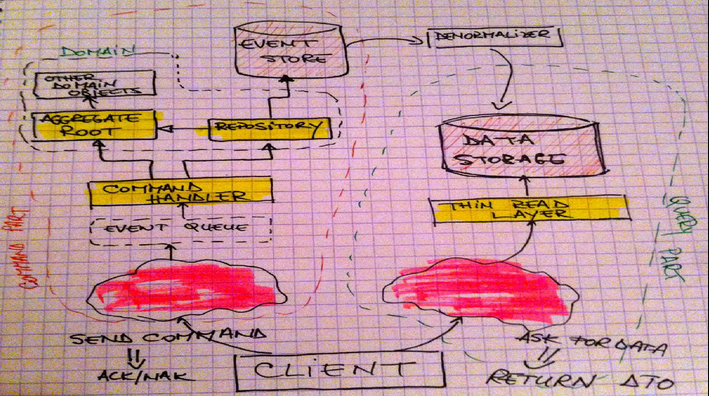
Dependiendo de la solución también puede ser un buen sitio donde usar Redis. Personalmente os dejo este enlace al podcast de We Developers donde hablan sobre el tema, por si queréis profundizar más.
Por último recomendación de teconologías a investigar para el tema, como son Eventric y bases de datos NoSql como MongoDB.
Delivery at Scale – Adrian Perreau de Pinninck, Manu Cupcic
La presentación está disponible aquí.
Habitualmente el coste del cambio aumenta conforme aumenta el número de desarrolladores, sobre todo en aplicaciones grandes con muchos desarrolladores y largos tiempos de compilación.
Nos presentaron su caso sobre una aplicación .Net, y pudimos ver la progresión y evolución del sistema.
Muchos de los problemas que contaban me sonaban muy familiares, ojalá hubiera tenido esta charla en el pasado.
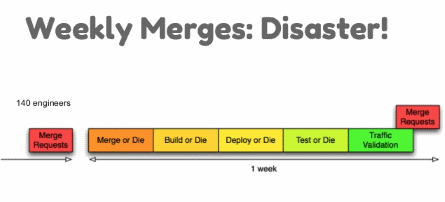
Os dejo más o menos la progresión que mostraron:
- Repositorio único y builds cada vez más largas.
- División en ramas por funcionalidad y problemas de mezclado de código.
- Validación de la rama principal cada vez en más tiempo, llegando a acumularse o producir bloqueos.
- Uso de NuGet para tratar el código como componentes independientes (Para los que no lo conozcan es el equivalente a Maven, pero en .Net).
- Equipos de gente por componentes.
- Encontrarse con nuevos problemas, como funcionalidades que afectan a varias cosas, interdependencias, grupos que no actualizaban ciertos componentes.
- Trunk Based Development y Branch by abstraction. Me quedo con la tarea de aprender más sobre esto.
- Revisiones de código con Gerrit, despliegues en sandbox, comprobaciones automáticas de métricas.
Por lo que nos contaron, la escal del proyecto debía ser ENORME, sin duda un reto brutal, y unas cuantas lecciones aprendidas por si nos encontramos alguna vez en algo parecido.
Testing en equipos infectados de test – Juan Gabardini
En principio también iba a participar Juan Diego Vasco Moncada, pero no pudo asistir.
Por mi parte yo también tenía interés en la charla, pero sólo asistí a los primeros veinte minutos, ya que no quise perderme la charla de Pablo Domingo.
En resumen, no puedo contar nada, así que aquí soy yo el que os pide información. Tendré que ver el vídeo si se grabó y en algún momento está disponible.
Flow Product Development – Pablo Domingo de La Orden
Abandoné el track de Dev Practices and Craftsmanship para ver la charla de Pablo en el track de Delighting Products, al que le debo para empezar el haber podido asistir a las conferencias.
Se enfrentaba a un gran reto ya que apenas contaba con 20 minutos para la exposición, y creo que le fue muy bien, aunque yo no sea muy objetivo.
Si me pedís opinión creo que 20 minutos no son suficientes para una charla, apenas puedes soltar un par de ideas, y las charlas de una hora o más corren mucho peligro de resultar pesadas si no se llevan muy bien.

La charla proponía en primer lugar ‘Tomar el pulso’ a cómo fluía el trabajo, y para ello expuso técnicas de observación del sistema.
Con el análisis de lo captado y basándonos en estudios como la Teoría de colas, propuso introducir cambios controlados (si metemos cambios drásticos tendremos que volver a empezar a medir) para mejorar el flujo de trabajo.
Era sorprendente ver con los datos que expuso, cómo una pequeña limitación en el Work in Progress resulta en que el trabajo fluya de otro modo.
Es muy difícil que yo os pueda contar toda la teoría y técnica que hay detrás de esta exposición, pero conociéndole estará encantado de resolver todas las dudas.
Estoy seguro de que también le interesará conocer el feedback de los asistentes, así que si alguno pasa por aquí hacédselo llegar o yo mismo puedo transmitírselo.
Vis-a-vis de Cristóbal Colón y Pedro Serrahima moderado por Jorge Uriarte
Gran cierre para la CAS 2014.
Cristóbal Colón es el presidente y fundador de La Fageda, os recomiendo encarecidamente que veáis el programa de Salvados donde es entrevistado.
Pedro Serrahima es Director ejecutivo de Pepephone. Encontraréis un montón de entrevistas e información sobre él y la cultura de Pepephone en internet.
Con lo dicho debería ser suficiente para que viérais la calidad de la discusión, donde se trató el significado de la empresas con Valores y con Principios.

Sólo puedo remitiros al vídeo cuando salga porque es muy difícil decir algo que aporte.
Os dejo también un enlace a los increibles apuntes visuales tomados por Javier Alonso y que también incluyen lo acontecido en el vis a vis.
Sé que es alucinante, pero como él mismo pide en Twitter, hacedle caso al contenido y no sólo al increible envoltorio.
Hasta el año que viene
Por último quiero decir que este recopilatorio de las charlas me ha supuesto un esfuerzo considerable, aunque personalemnte he tenido un beneficio inmediato escribiendo, ya que he reforzado mucho de lo aprendido.
Espero ya de paso que pueda servir como pequeño granito de arena en forma de aportación a la comunidad, animando a los que tenían interés o ayudando a los que no han podido asistir.
Y si a mí me ha costado escribir estos dos post, no quiero ni pensar lo que les habrá costado a los ponentes preparar sólo una de las charlas.
De verdad que detrás de estos dos días ha habido mucho trabajo, muchas gracias a todos.
Gracias también a toda la organización por traernos todo este conocimiento, y a la ayuda de los voluntarios, que han conseguido coordinar y facilitar esos dos días de forma espectacular.
Bueno, ¡y queda lo mejor! tras este resumen me siento libre para contaros al fin lo verdaderamente importante de la conferencia, los momentos y experiencias vividas, desde un punto de vista mucho más personal. ¡Nos vemos pronto!